This connector is available as a built-in connector on StreamNative Cloud.
- For a quick start on setting up and using the connector, refer to the Quick Start section. It provides a step-by-step guide to get you up and running quickly.
- To understand the internal workings of the connector, see the Data Sink Workflow. This section explains how data flows from Pulsar to Snowflake.
- The Pulsar Snowflake Streaming Sink Connector supports exactly-once semantics, ensuring data is processed without duplication. Learn how this is achieved in the Exactly-Once Semantics section.
- For insights into how the connector maintains reliability and handles errors, check the Fault Tolerance section. It describes mechanisms for recovering from failures.
- To learn how to configure the connector to suit your needs, see the Configuration section. It provides details on all available settings and options.
- For instructions on how to sink data into an Iceberg table, visit the Sink Data into the Iceberg Table section. This part covers the steps required to integrate with Iceberg tables.
Quick start
This section introduces how to get started with creating a Snowflake streaming sink connector and get it up and running.Prerequisites
The prerequisites for connecting a Snowflake streaming sink connector to external systems include:- Prepare a snowflake account
-
Get the account URL from the
Admin - Accountspage and click the link. It should be the format likehttps://<account_identifier>.snowflakecomputing.com. -
Generate the public key and private key for the authentication. For more details, please
check this guide
It will generate
rsa_key.p8(the private key) andrsa_key.pub(the public key) locally. -
Log in and configure the public key.
See Installing SnowSQL to install the SnowSQL.
The
-ais followed by an account identifier, which is a substring of the account URL before. The-uis followed by your username. After logging in, set the public key passphrase:You can get the public key passphrase(MIIBIjA…)by running the following command:
1. Create Snowflake objects and grant permission
Before creating the connector, you need to grant the permissions in Snowflake. Write the following content into a file, e.g. name it withgrant.sql. The script creates a user snservice that will be used in the sink config later and
associate it with a role snrole that is only used in Snowflake internally. Then it grants the necessary permissions.
2. Create a connector
The following command shows how to use pulsarctl to create abuiltin
connector. If you want to create a non-builtin connector,
you need to replace --sink-type snowflake with --archive /path/to/pulsar-io-snowflake.nar. You can find the button
to download the nar package at the beginning of the document.
If you are a StreamNative Cloud user, you
need set up your environment first.
--sink-config is the minimum necessary configuration for starting this connector, and it is a JSON string. You
need to substitute the relevant parameters with your own.
You can get the private key passphrase (MIIBIjA…) by running the following command:
You can also choose to use a variety of other tools to create a connector:
- pulsar-admin: The command arguments for
pulsar-adminare similar to those ofpulsarctl. You can find an example for StreamNative Cloud Doc. - RestAPI: You can find an example for StreamNative Cloud Doc.
- Terraform: You can find an example for StreamNative Cloud Doc.
- Function Mesh: The docker image can be found at the beginning of the document.
3. Send messages to the topic
If your connector is created on StreamNative Cloud, you need to authenticate your clients.
See Build applications using Pulsar clients for
more information.
4. Check the data on Snowflake table
First, you need to execute the following SQL command to grant the roleSNROLE to the user you logged in.
SNROLE, under Data - Database - ST_TUTS - DEMO - Tables you will find table
PERSISTENT___PUBLIC_DEFAULT_INPUT_SNOWFLAKE_1118738946 is created and records the messages produced above.
Configuration
This table outlines all the properties and the descriptions.While running the connector, please make sure the retain ordering is enabled:
retainOrdering=true. If you create the
connector on SNCloud, retain ordering is enabled by default and cannot be
disabled. For why retain ordering is necessary, see Data sink workflow.Authentication
The Snowflake streaming sink connector supports authenticating with Snowflake using a private key. Please complete the key pair authentication instructions described in Snowflake key pair rotation. After that, you can get copy the entire private key and set it into the configurationprivateKey.
If you are setting up the connector on the SNCloud UI, you need to create a secret to store the private key. The private
key should not have any headers or footers; it must be a base64 encoded string.
You can get your private key using the following command:
Table name mapping
When using the Pulsar Snowflake Streaming Connector, Pulsar topics can be mapped to existing Snowflake tables. If no mapping is specified, the connector will create a new table for each topic based on the topic’s name. Note that if theicebergEnabled is true, the connector won’t create the table and will throw an exception if the table is not exist.
The connector converts the topic name into a valid Snowflake table name using the following rules:
- Lowercase topic names are converted to uppercase for table names.
- If the first character of the topic name is not a letter (a-z, A-Z) or an underscore (_), an underscore is added at the beginning of the table name.
-
Any character in the topic name that is not valid for a Snowflake table name is replaced with an underscore. For more
information on valid characters,
see Snowflake’s identifier requirements. For
example, the topic name
test-topicwould becomeTEST_TOPIC.
numbers+x and numbers-x would both become NUMBERS_X. To prevent
duplication, the connector appends a unique suffix to the table name, consisting of an underscore and a generated hash
code.
You can use the configuration parameter topic2table to specify a mapping between topics and tables. The parameter
value is a comma-separated list of topic-table pairs, where each pair is separated by a colon. For example:
Schema detection and evolution
The Connector offers support for schema detection and evolution. Snowflake table structures can be automatically defined and adjusted to accommodate new data structures loaded by the connector. To enable schema detection and evolution for this setup, configure the following configuration:enableSchematization is true and the table has the
ENABLE_SCHEMA_EVOLUTION enabled. You can set it by running the following SQL command:
Ingestion Latency
There are two configuration parameters determining the ingestion latency of the Snowflake streaming sink connector:maxClientLag: This parameter specifies how often the Snowflake Ingest SDK flushes data to Snowflake, in seconds. If you find the delay for the connector to load data to the Snowflake table too long, you can reduce this value. However, setting it too low will result in more frequent data flush operations and result in a worse query performance. For more instruction for configuring themaxClientLag, please see Latency recommendations¶.- Specify it to 0 or leave it empty to let the connector decide the value based on the table type:
- For the standard snowflake table, the default value is 1 second.
- For the Iceberg table, the default value is 30 seconds.
- Specify it to 0 or leave it empty to let the connector decide the value based on the table type:
checkCommittedMessageIntervalMs: This parameter specifies how often the connector checks for committed messages and acknowledge them in the Pulsar, in milliseconds. The default value is 1 second.
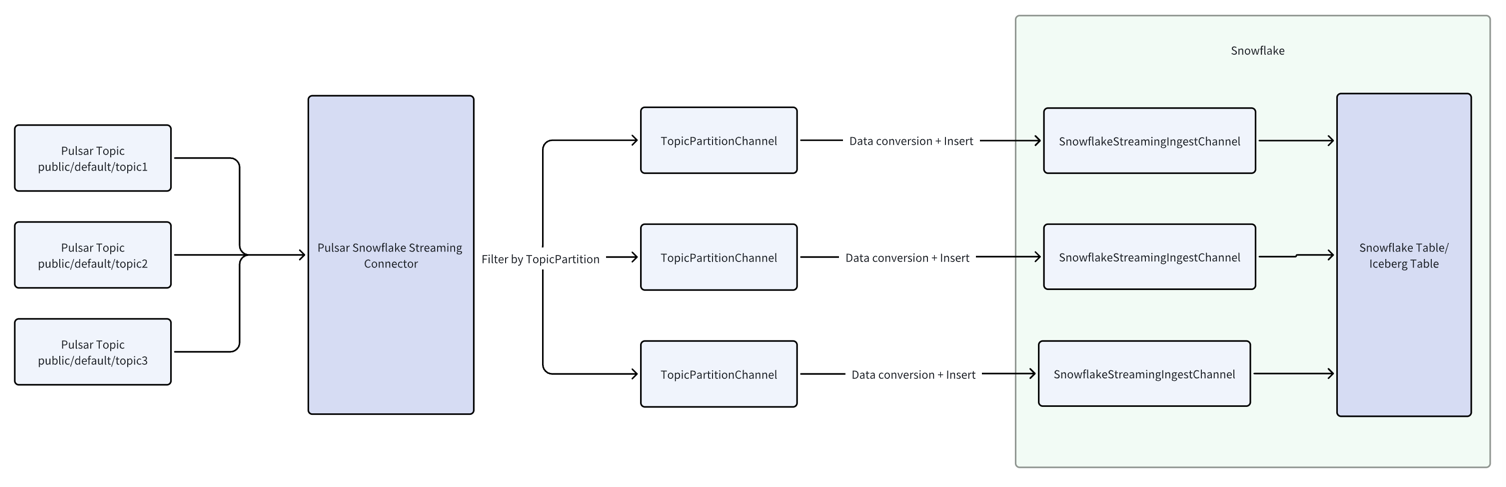
Data sink workflow
The diagram below illustrates the data sink flow for the Pulsar Snowflake Streaming connector:- The connector subscribes to multiple user-specified topics and consumes messages from them.
- It filters messages by topic-partition and forwards them to the corresponding TopicPartitionChannel. Each
TopicPartitionChannel corresponds to a topic-partition. The connector creates a Snowflake Streaming Ingest channel
for
each TopicPartitionChannel to ingest data into Snowflake. For example, if there is a partitioned topic
test-topicwith 3 partitions, the connector will create 3 TopicPartitionChannels:test-topic-partition-0,test-topic-partition-1, andtest-topic-partition-2. - Within each TopicPartitionChannel, the RecordService converts messages into Snowflake records and inserts them into the Snowflake Streaming Ingest channel, which then ingests the data into Snowflake.
Exactly-once semantics
Currently, the Snowflake streaming sink connector supports theexactly-once delivery guarantee semantic.
Exactly-once semantics ensure the delivery of Pulsar messages without duplication or data loss.
The connector uses a one-to-one mapping between partitions and channels, utilizing the Message ID and the Snowflake
Channel Offset Token to achieve exactly-once semantics. For more information,
see Snowflake Offset Token.
The connector uses the Message ID as the offset token. For instance, the message ID 0:4:1:3 (Ledger ID: 0; Entry ID:
4; Partition Index: 1; Batch Index: 3) is converted to the offset token 0:4:1, discarding the partition index. This
offset token is used each time messages are inserted into Snowflake. When the Snowflake SDK flushes the data, the last
committed offset token of the channel is updated, and the connector retrieves it from the SDK.
With retainOrdering enabled, the connector ensures that messages in each TopicPartitionChannel are received in order
without skips.
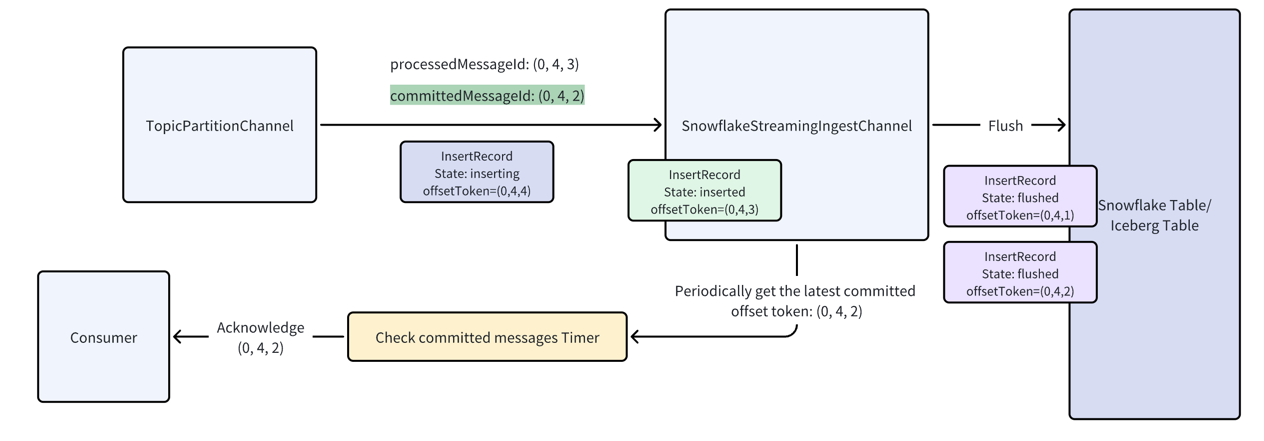
When opening each TopicPartitionChannel, the Snowflake Streaming Ingest channel is opened, retrieving the last committed
offset token, which is stored as committedMessageId. Another variable, processedMessageId, is updated after each
data insert. The connector discards all messages before the current processedMessageId. It periodically checks the
last committed offset token and updates lastCommittedMessageId, acknowledging all committed messages if
lastCommittedMessageId changes.
Here is an example diagram to show how it works:
Suppose the current processMessageId and the lastCommittedMessageId are both 0:4:0.
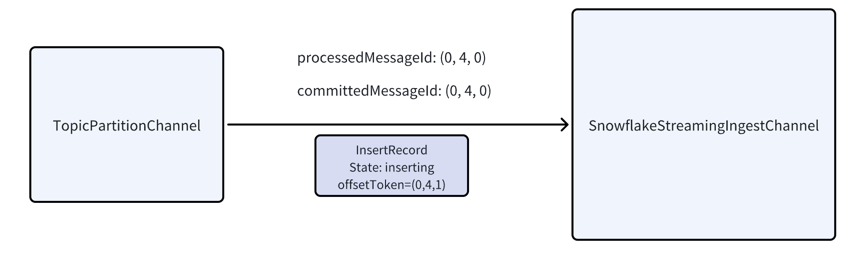
processedMessageId, the connector inserts it into the
Snowflake channel and updates processedMessageId to 0:4:1.:
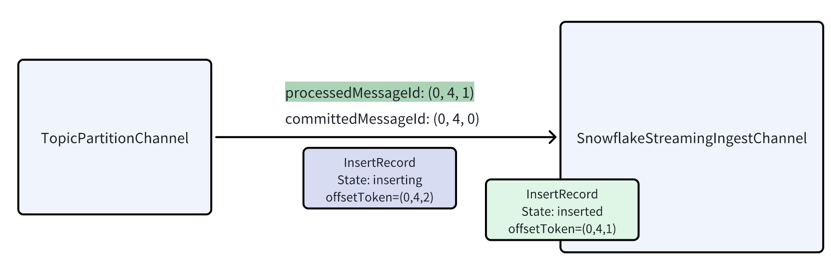
0:4:0 comes in again, it will happen due to the consumer redelivery or some
retry operations. The connector discards it as its message id is less than processedMessageId.
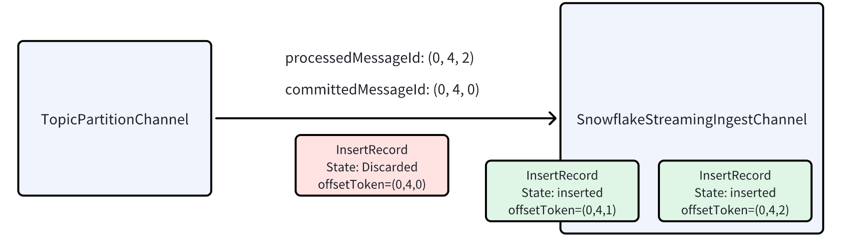
0:4:2. And a dedicated timer will periodically check the last committed offset token and update the
lastCommittedMessageId. The periodicity is determined by the configuration checkCommittedMessageIntervalMs.
Once the Snowflake channel flushes data, the last committed offset token updates to 0:4:2. A timer periodically checks
this token, updating lastCommittedMessageId. If it changes, the connector acknowledges all messages before
lastCommittedMessageId using the cumulative acknowledgment:
Schema
Supported Pulsar Schema
The snowflake streaming sink connector supports converting some of Pulsar schemas, as listed in the following table.Table format
If you don’t enable the schema detection and evolution, the Snowflake table loaded by the Pulsar connector contains only two VARIANT columns:RECORD_CONTENT and RECORD_METADATA.
RECORD_CONTENT: The content of the message. The type of the content isVARIANT.RECORD_METADATA: The metadata of the message. The type of the metadata isVARIANT..
metadataFields to specify the metadata fields for each Snowflake record. The default value
is message_id,partition,topic,publish_time. And the supported fields are schema_version, partition, event_time,
publish_time, message_id, sequence_id, producer_name, topic.
If enableSchematization is true and the message is a primitive type, the connector will store the message in the
RECORD_CONTENT column.
Standard snowflake table type mapping
If the schema detection and evolution are enabled, the connector will create and alter the table based on the avro schema type of the message’s field. The following table shows the mapping between the field’s schema and the Snowflake table.
Here is the mapping for the Avro logical type:
Other types are not supported and will throw an exception.
Iceberg table type mapping
If theicebergEnabled is true and schema detection and evolution are enabled, the connector will alter the Iceberg
table based on the avro schema type of the message’s field. The following table shows the mapping between the field’s
schema and the Snowflake table.
The Iceberg table doesn’t support nested types like ARRAY, RECORD, and UNION.
Here is the mapping for the Avro logical type:
Other types are not supported and will throw an exception.
Fault tolerance
The connector can guarantee messages are neither duplicated nor silently dropped. If there are any errors during the messages processing, the connector will simply get restarted and reprocess the messages from the last committed messages.Sink data into the Iceberg table
The Snowflake streaming sink connector supports sinking data into the Iceberg table. To enable the Iceberg table format, set theicebergEnabled configuration to true.
icebergEnabled is set to true, the connector will automatically update the Iceberg table based on the Avro
schema of the message fields. If not, you need to manually update the table to match the Pulsar Avro Schema Type.
For the schema mapping for the Iceberg table, please refer to
the Iceberg table type mapping.
Here is a simple example to create an Iceberg table:
ENABLE_SCHEMA_EVOLUTION enabled if you wants the connector to
automatically evolve the schema. You can set it by running the following SQL command:
RECORD_METADATA column and match the types as shown in the example.