Introduction to Kafka Connect
Concept
Kafka Connect is an integration tool that is released with the Apache Kafka project. It provides reliable data streaming between Apache Kafka and external systems and is both scalable and flexible. Kafka Connect works with Kafka on Pulsar (KoP), which is compatible with the Kafka API. Kafka Connect uses Source and Sink connectors for integration. Source connectors stream data from an external system to Kafka, while Sink connectors stream data from Kafka to an external system. The following diagram illustrates the data movement among source connectors, Pulsar Kop, sink connectors, and external systems.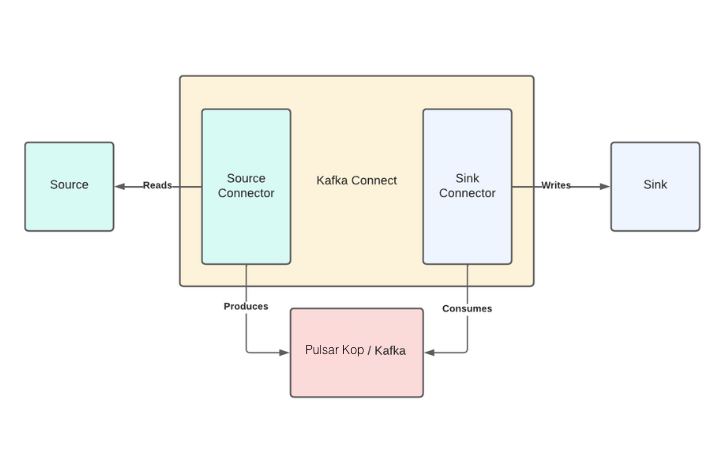
Benefits
- Seamless & Simplified Data Integration: Kafka Connect provide a unified interface for connecting Kop to various external systems and data sources, allowing developers to easily integrate Kop with their existing infrastructure without the need for custom integration code.
- Extensibility: Kafka Connect are designed to be easily extensible, allowing developers to create custom connectors for specific use cases and data sources not covered by the built-in connectors.
- Reduced Development Effort: By leveraging pre-built connectors, developers can save time and effort. They don’t have to write and maintain complex integration code from scratch for each external system.
- Reliable and Scalable: Kafka Connect are built to be reliable and scalable, ensuring the data transfers between Kop and external systems are efficient and fault-tolerant.
Use cases
- Data Ingestion to Pulsar Kop: If you have data coming from various external sources, such as databases, message queues, or cloud storage systems like Amazon S3, you can use Kafka Connect to ingest that data into Kop topics.
- Data Export from Pulsar Kop: Kafka Connect also enable you to export data from Kop topics to other systems or storage solutions. This helps you to synchronize data across different environments, replicate data, or stream data to external services or databases.
- Real-time Data Processing: Kafka Connect facilitate real-time data processing by enabling the seamless movement of data between Kop and other systems. This is particularly useful in event-driven architectures, streaming applications, and microservices-based solutions.
- Extending Kop’s Functionality: If you have specific use cases or data sources not directly supported by Kop, you can deploy custom Kafka Connect to extend Kop’s functionality and integrate with those systems.
Connectors Shared Responsibility
StreamNative and our customers have a shared responsibility for maintaining and keeping connectors properly functioning. Outlined below, StreamNative has a responsibility for custom connectors that are maintained by uploading to StreamNative Cloud to maintain connectivity to the Pulsar Kop cluster and for logging and monitoring. Customers who upload their connectors are responsible for all other operations such as configurations, updates, development, support and plugin installation. Partner connectors have similar support but the partners with StreamNative will be responsible for development and connector support. For built in connectors, StreamNative is responsible for everything except connector configuration. For more details, see below.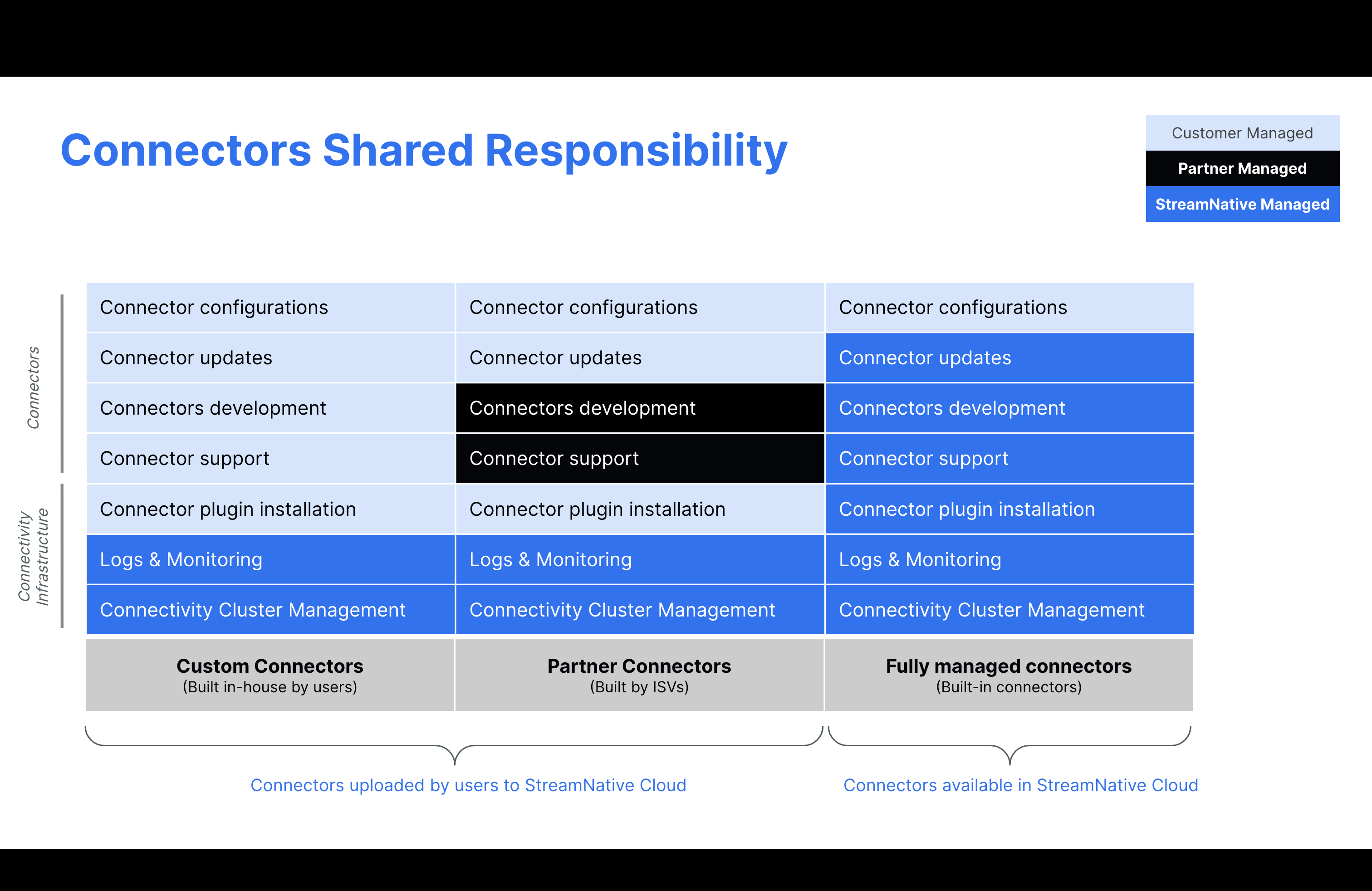
Built-in connectors on StreamNative Cloud
To further reduce the development overhead and time, StreamNative has pre-built a variety of Kafka connect on StreamNative Cloud. With proper configurations, you can integrate the data between your Pulsar Kop cluster on StreamNative Cloud and your data systems effortlessly.Built-in source connectors
Currently, StreamNative Cloud supports the following kafka source connectors:- MongoDB source connector
- YugabyteDB CDC source connector
- Datagen source connector
- Cosmos DB source connector
- Debezium MongoDB source connector
- Debezium Mysql source connector
- Debezium PostgreSql source connector
- Debezium Spanner source connector
- Google Pub/Sub source connector
- Google Pub/Sub Lite source connector
- Debezium SqlServer source connector
- JDBC source connector
- JR source connector
Built-in sink connectors
Currently, StreamNative Cloud supports the following kafka sink connectors.- Iceberg sink connector
- Milvus sink connector
- MongoDB sink connector
- BigQuery sink connector
- Cosmos DB sink connector
- ElasticSearch sink connector
- Snowflake sink connector
- JDBC sink connector
- Debezium JDBC sink connector
- Google Pub/Sub sink connector
- Google Pub/Sub Lite sink connector
- Google Cloud Storage sink connector
- Google Bigtable sink connector
Self-hosted Kafka Connect
Despite the fact that StreamNative Cloud supports fully managed Kafka Connect connectors, you can still self-host Kafka Connect connectors in your own environment. See the Kafka Connect QuickStart for how to configure your own Kafka Connect connectors to connect to your StreamNative cluster.What’s next?
- Deploy kafka connectors
- Manage kafka connectors
- Monitor and troubleshoot kafka connectors
- SMTs(Single Message Transformations)
- Discover kafka Connect Ecosystem on StreamNative Hub.