This feature is currently in private preview. If you want to try it out or have any questions, submit a ticket to the support team.
Tutorial Overview
This tutorial provides a comprehensive walkthrough on enabling Lakehouse Storage on StreamNative Private Cloud. It covers essential steps such as offloading data to Lakehouse products, streaming reads from Lakehouse, and batch reads from Lakehouse, offering a holistic understanding of the integration.Step 1: Enable Lakehouse Storage on Private Cloud
Prerequisites
Before activating the Lakehouse Storage feature, ensure you have a prepared S3 or GCS bucket with necessary permissions for your AWS or GCP account. Follow the AWS S3 or GCP GCS documentation to create the bucket and grant appropriate permissions.Activation Process
To enable Lakehouse Storage, configure theconf/broker.conf and conf/offload.conf files within the Pulsar broker environment.
In conf/broker.conf, include the following configurations:
| Configuration | Description | Required | Default Value |
|---|---|---|---|
| managedLedgerOffloadDriver | Case-insensitive offloader driver name (e.g., delta or iceberg) | Yes | N/A |
conf/offload.conf, add the following configurations:
| Configuration | Description | Required | Default Value |
|---|---|---|---|
| metadataServiceUri | Metadata service URI for BookKeeper client (e.g., zk://localhost:2181/ledgers) | Yes | N/A |
| pulsarWebServiceUrl | Pulsar web service URL (e.g., http://localhost:8080) | Yes | N/A |
| pulsarServiceUrl | Pulsar protocol service URL (e.g., pulsar://localhost:6650) | Yes | N/A |
| offloadProvider | Offloader driver’s name (e.g., delta or iceberg) | Yes | N/A |
| storagePath | Storage path (e.g., s3a://bucket-name/prefix or gs://bucket-name/prefix) | No | data |
| googleCloudProjectID | GCS offload project configuration. For example: example-project | Required if offloading data to GCS | N/A |
| googleCloudServiceAccountFile | GCS offload authentication. For example: /Users/user-name/Downloads/project-804d5e6a6f33.json | Required if offloading data to GCS | N/A |
AWS_ACCESS_KEY_ID and AWS_SECRET_KEY before starting up the broker service and setting the storagePath with s3s:// prefix.
Lakehouse product like Delta Lake is supported, with data typically written in parquet format with snappy compression. Specify the offload provider (delta or iceberg) in conf/offload.conf to choose the Lakehouse product.
Upon completing these configurations, start the Pulsar broker to initiate the Lakehouse tiered storage offload service.
After finished the above steps, the Lakehouse Storage feature will be support on your Pulsar cluster. But this feature is still not enabled by default on the Pulsar cluster, you need to enable it on namespace level by setting namespace offload threshold.
For example:
Set the offload threshold to 0 by pulsar-admin, which means all the data will be offloaded to Lakehouse immediately.
Step 2: Offload Data to Lakehouse
Once Lakehouse Storage is enabled for your namespace or cluster, produce messages to your topic for automatic offloading to the Lakehouse table. Note that the current support is limited to AVRO schema and Pulsar primitive schema, with other schemas under development. For testing, usepulsar perf to produce messages to a topic:
pulsar-admin:
__OFFLOAD cursor if the offload process started
offloaded flag, if the ledger has been offloaded to Lakehouse, the offloaded flag will be set to true.
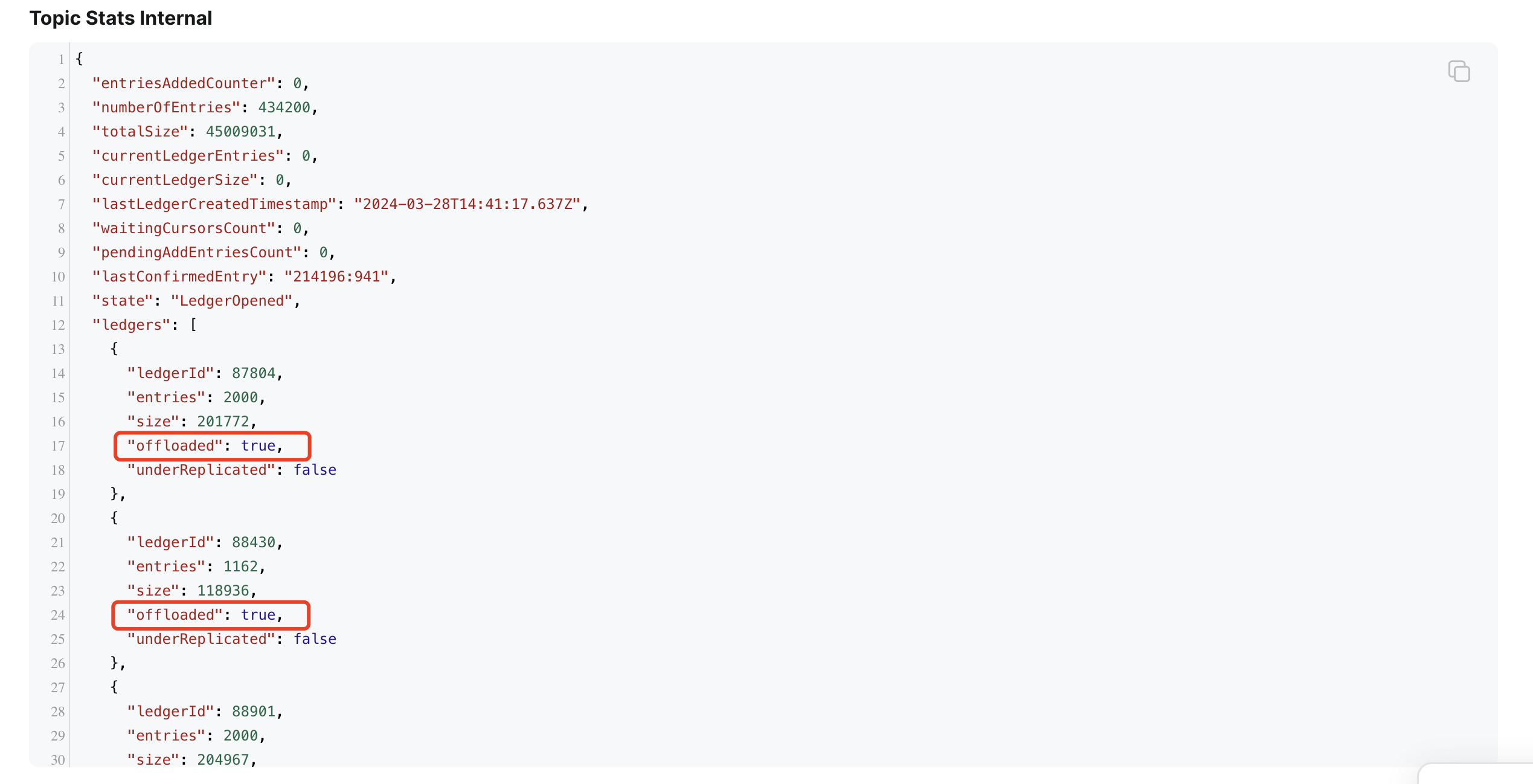
Note: The topic offload processor is triggered by ledger rollover, after the offload process triggered, it will offload the following ledgers in streaming mode and do not need to wait for ledger rollover. So when you produce messages to the topic and the first ledger not rolled over, the offload process will not start.
Step 3: Read Data from Lakehouse
After data is offloaded to Lakehouse, you can read it using the Kafka or Pulsar reader/consumer API or the Lakehouse table API.Streaming Read
You can continue to use the Pulsar or Kafka API to read data from the topic even when the data is written in Lakehouse table formats. For example, you can create a reader/consumer using the Pulsar client to read data seamlessly. For testing, consume messages from a topic usingpulsar perf:
Read as a Lakehouse table
You can use Spark SQL, Athena, Trino, or other tools to read Delta table data from the S3 or GCS bucket. The bucket is owned by the user, and the data is stored in the bucket.Disable Lakehouse Storage
If you want to disable the Lakehouse Storage feature, set the offload threshold to -1 usingpulsar-admin: