
Pulsar Spark Connector is an integration of Apache Pulsar and Apache Spark (data processing engine), which allows Spark to read data from Pulsar and write data to Pulsar using Spark structured streaming and Spark SQL and provides exactly-once source semantics and at-least-once sink semantics.

How it Works
This illustration shows how the Pulsar Spark source connector transfers data from a Pulsar topic to a Spark job.
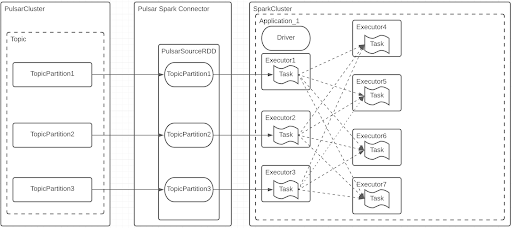
As you can see from the above illustration, each Pulsar topic partition is mapped into a PulsarSourceRDD partition. When a Spark job executes a new microbatch, the Pulsar Spark connector requests new data from Pulsar for each PulsarSourceRDD partition. In the Spark cluster, the data request tasks are assigned to available executors. All of the available data for each partition since the last consumption are read from the Pulsar topic partition. And, the Spark job continuously creates new microbatches in a user-defined triggering interval and processes the fetched data accordingly. This process repeats until the Spark job is canceled. Once the data is fetched, you can do any operations, including shuffling.
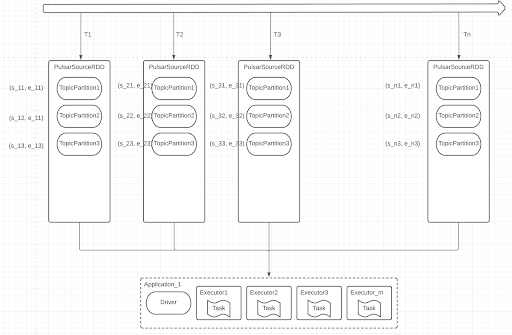
After a microbatch, the offset is committed. Therefore, the next microbatch starts with newly incoming data since the last offset.
For failure recovery, the offsets of each partition are stored into the Spark’s checkpoint. And each time a Spark job is launched, it first tries to restore reading offsets from the state store. If there are offsets saved for this job, the Spark job reads data from the saved offsets. Otherwise, the Spark job reads data from a user-defined position of the topic.
The whole life cycle of a structured streaming job is illustrated in the figure below. As time goes by, each interval yields a new microbatch of data that is then processed by the Spark job.
How to configure
You can set the following configurations for the Pulsar Spark connector (both source and sink).
Pulsar Spark source configuration
For the Pulsar Spark source, you can set the following configurations for both batch and streaming queries.
| Configuration | Value | Required / Optional | Default | Query type | Description |
|---|---|---|---|---|---|
topic | A topic name string | Required | N/A | Streaming and batch queries | The topic to be consumed. This option is exclusive to the topics and topicsPattern options. |
topics | A comma-separated list of topics | Required | N/A | Streaming and batch queries | The list of topics to be consumed. This option is exclusive to the topic and topicsPattern options. |
topicsPattern | A Java regex string | Required | N/A | Streaming and batch queries | The pattern used to subscribe to topic(s). This option is exclusive to the topic and topics options. |
service.url | A service URL of your Pulsar cluster | Required | N/A | Streaming and batch queries | The Pulsar serviceUrl configuration. |
admin.url | A service HTTP URL of your Pulsar cluster | Required | N/A | Streaming and batch queries | The Pulsar serviceHttpUrl configuration. |
startingOffsets | <br />- "earliest" (streaming and batch queries) <br />- "latest" (streaming query) <br />- A JSON string, such as """ {""topic-1"":[8,11,16,101,24,1,32,1],""topic-5"":[8,15,16,105,24,5,32,5]} """ | Optional | <br>/"- batch query: earliest" <br />- Streaming query: "latest" | Streaming and batch queries | The startingOffsets option specifies the position where a Reader reads data from.<br><br>"earliest": the Reader reads all the data in the partition, starting from the very beginning.<br><br>"latest": the Reader reads data from the newest records that are written after the Reader starts running.<br><br>A JSON string: specifies a starting offset for each topic. You can use org.apache.spark.sql.pulsar.JsonUtils.topicOffsets(Map[String, MessageId]) to convert a message offset to a JSON string.<br><br>Note:<br><br>For the batch query, the "latest" option is not allowed, either implicitly specified or use MessageId.latest ([8,-1,-1,-1,-1,-1,-1,-1,-1,127,16,-1,-1,-1,-1,-1,-1,-1,-1,127]) in JSON.<br><br>For the streaming query, the "latest" option applies only when a new query is started, and the resuming always picks up from where the query left off. Newly discovered partitions during a query will start at "earliest". |
endingOffsets | <br />- "latest"" (batch query) <br />- A JSON string, such as "topic-1":[8,12,16,102,24,2,32,2],"topic-5":[8,16,16,106,24,6,32,6]} | Optional | "latest" | Batch query | The endingOffsets option specifies where a Reader stops reading data.<br />- "latest": the Reader stops reading data at the latest record.<br />- A JSON string: specifies an ending offset for each topic.<br><br>Note:<br><br> MessageId.earliest ([8,-1,-1,-1,-1,-1,-1,-1,-1,-1,1,16,-1,-1,-1,-1,-1,-1,-1,-1,-1,1]) is not allowed. |
failOnDataLoss | <br />-true<br />- false | Optional | true | Streaming query | Specify whether to fail a query when data is lost (For example, topics or messages are deleted because of the retention policy). This may cause a false alarm. You can set it to false when it does not work as you expected. A batch query always fails if it fails to read any data from the provided offsets due to data loss. |
allowDifferentTopicSchemas | Boolean value | Optional | false | Streaming query | If it is set to false, schema-based topics are not automatically deserialized, when multiple topics with different schemas are read. In that way, topics with different schemas can be read in the same pipeline, which is then responsible for deserializing the raw values based on some schema. Since only the raw values are returned when it is set to true, Pulsar topic schema(s) are not taken into account during operation. |
pulsar.client.* | Pulsar client related settings | Optional | N/A | Streaming and batch queries | A Pulsar client instance is shared among all threads within one executor. You can set Pulsar client related settings with pulsar.client.* option. |
pulsar.reader.* | Pulsar Reader related settings | Optional | N/A | Streaming and batch queries | Data in Pulsar topics are read out using the Pulsar Reader API. Therefore, you can configure Reader-related settings by specifying the pulsar.reader.* option. |
Schema of Pulsar Spark source
- For Pulsar topics without schema or with primitive schema, messages' payloads are loaded to a
valuecolumn with the corresponding Pulsar schema type. - For topics with Avro or JSON schema, their field names and field types are kept in the result rows.
- If the
topicsPatternmatches topics that have different schemas, then settingallowDifferentTopicSchemastotrueallows the Pulsar Spark source to read this content in a raw form. In this case, it is the responsibility of the pipeline to apply the schema on this content, which is loaded to thevaluecolumn.
In addition to the above points, each row in the Pulsar Spark source has the following metadata fields.
| Column | Type |
|---|---|
__key | Binary |
__topic | String |
__messageId | Binary |
__publishTime | Timestamp |
__eventTime | Timestamp |
__messageProperties | Map < String, String > |
Example
In Pulsar, a topic with AVRO schemas looks like the following:
case class Foo(i: Int, f: Float, bar: Bar)
case class Bar(b: Boolean, s: String)
val s = Schema.AVRO(Foo.getClass)
When the data is exported to a Spark DataFrame/DataSet, it looks like the following:
root
|-- i: integer (nullable = false)
|-- f: float (nullable = false)
|-- bar: struct (nullable = true)
| |-- b: boolean (nullable = false)
| |-- s: string (nullable = true)
|-- __key: binary (nullable = true)
|-- __topic: string (nullable = true)
|-- __messageId: binary (nullable = true)
|-- __publishTime: timestamp (nullable = true)
|-- __messageProperties: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)
Here is another example how Pulsar data with Schema.DOUBLE schema looks like in the Spark DataFrame:
root
|-- value: double (nullable = false)
|-- __key: binary (nullable = true)
|-- __topic: string (nullable = true)
|-- __messageId: binary (nullable = true)
|-- __publishTime: timestamp (nullable = true)
|-- __eventTime: timestamp (nullable = true)
|-- __messageProperties: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)
Pulsar Spark sink configuration
For Pulsar Spark sink, you can set the following configurations for both batch and streaming queries.
| Configuration | Value | Required / Optional | Default | Query type | Description |
|---|---|---|---|---|---|
service.url | A service URL of your Pulsar cluster | Required | N/A | Streaming and batch queries | The Pulsar serviceUrl configuration. |
admin.url | A service HTTP URL of your Pulsar cluster | Required | N/A | Streaming and batch queries | The Pulsar serviceHttpUrl configuration. |
topic | A topic name string | Optional | N/A | Streaming and batch queries | If specified, each record is written to the same topic specified by this parameter. Otherwise, you should construct a __topic column for each record used for message routing. |
failOnDataLoss | <br />-true<br />- false | Optional | true | Streaming query | Specify whether to fail a query when data is lost (For example, topics or messages are deleted because of the retention policy). This may cause a false alarm. You can set it to false when it does not work as you expected. A batch query always fails if it fails to read any data from the provided offsets due to data loss. |
pulsar.client.* | Pulsar client related settings | Optional | N/A | Streaming and batch queries | A Pulsar client instance is shared among all threads within one executor. You can set Pulsar client related settings with pulsar.client.* option. |
pulsar.producer.* | Pulsar Producer related settings | Optional | N/A | Streaming and batch queries | Data in Pulsar topics is actually written out using the Pulsar Producer API. Therefore, you can configure Producer-related settings by specifying the pulsar.producer.* option. |
Security configurations
If the Pulsar cluster requires authentication, you can set credentials in any of the following ways.
Scenario 1
When a Pulsar cluster is enabled with authentication and the Pulsar client and Pulsar Admin use the same credential, you can configure the Spark connector as below:
val df = spark
.readStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("pulsar.client.authPluginClassName","org.apache.pulsar.client.impl.auth.AuthenticationToken")
.option("pulsar.client.authParams","token:<valid client JWT token>")
.option("topicsPattern", "sensitiveTopic")
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
service.url: the service URL of your Pulsar clusteradmin.url: the HTTP URL of your Pulsar clusterpulsar.client.authParams: the JWT token used for authentication, in a format oftoken:<your_JWT_token>
Scenario 2
When a Pulsar cluster is enabled with authentication and the Pulsar client and Pulsar Admin use different credentials, you can configure the Spark connector as below:
val df = spark
.readStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("pulsar.admin.authPluginClassName","org.apache.pulsar.client.impl.auth.AuthenticationToken")
.option("pulsar.admin.authParams","token:<valid admin JWT token>")
.option("pulsar.client.authPluginClassName","org.apache.pulsar.client.impl.auth.AuthenticationToken")
.option("pulsar.client.authParams","token:<valid client JWT token>")
.option("topicsPattern", "sensitiveTopic")
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
service.url: the service URL of your Pulsar clusteradmin.url: the HTTP URL of your Pulsar clusterpulsar.admin.authParams: the JWT token used for Pulsar Admin authentication, in a format oftoken:<your_admin_JWT_token>pulsar.client.authParams: the JWT token used for Pulsar client authentication, in a format oftoken:<your_client_JWT_token>
Scenario 3
When a Pulsar cluster is enabled with TLS authentication and the Pulsar client and Pulsar Admin use different credentials, you can configure the Spark connector as below:
val df = spark
.readStream
.format("pulsar")
.option("service.url", "pulsar+ssl://localhost:6651")
.option("admin.url", "http://localhost:8080")
.option("pulsar.admin.authPluginClassName","org.apache.pulsar.client.impl.auth.AuthenticationToken")
.option("pulsar.admin.authParams","token:<valid admin JWT token>")
.option("pulsar.client.authPluginClassName","org.apache.pulsar.client.impl.auth.AuthenticationToken")
.option("pulsar.client.authParams","token:<valid client JWT token>")
.option("pulsar.client.tlsTrustCertsFilePath","/path/to/tls/cert/cert.pem")
.option("pulsar.client.tlsAllowInsecureConnection","false")
.option("pulsar.client.tlsHostnameVerificationenable","true")
.option("topicsPattern", "sensitiveTopic")
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
service.url: the service URL of your Pulsar clusteradmin.url: the HTTP URL of your Pulsar clusterpulsar.admin.authParams: the JWT token used for Pulsar Admin authentication, in a format oftoken:<your_admin_JWT_token>pulsar.client.authParams: the JWT token used for Pulsar client authentication, in a format oftoken:<your_client_JWT_token>pulsar.client.tlsTrustCertsFilePath: the path to the certification file. The certificate file must be at the specified path on every machine of the Pulsar cluster.
How to deploy
You can use one of the following methods to use the Pulsar Spark connector and you need to configure it before using the connector.
- Client library: you can use all the features of Pulsar Spark connector (Java and Scala).
- CLI: you can use all the features of Pulsar Spark connector in interactive mode (Scala).
Client library
As with any Spark applications, spark-submit is used to launch your application. You can use the --packages option to add pulsar-spark-connector_{{SCALA_BINARY_VERSION}} and its dependencies directly to spark-submit.
Example
./bin/spark-submit
--packages io.streamnative.connectors:pulsar-spark-connector_{{SCALA_BINARY_VERSION}}:{{PULSAR_SPARK_VERSION}}
--repositories https://dl.bintray.com/streamnative/maven
...
CLI
For experimenting on spark-shell (or pyspark for Python), you can also use the --packages option to add pulsar-spark-connector_{{SCALA_BINARY_VERSION}} and its dependencies directly.
Example
./bin/spark-shell
--packages io.streamnative.connectors:pulsar-spark-connector_{{SCALA_BINARY_VERSION}}:{{PULSAR_SPARK_VERSION}}
--repositories https://dl.bintray.com/streamnative/maven
...
When locating an artifact or library, the --packages option checks the following repositories in order:
Local maven repository
Maven central repository
Other repositories specified by the
--repositoriesoption
The format for the coordinates should be groupId:artifactId:version.
Tip
For more information about submitting applications with external dependencies, see application submission guide.
How to use
This section describes how to create Pulsar Spark source and sink connectors to transmit data between the Pulsar cluster and the Spark cluster.
Read data from Pulsar
The section describes how to create a Pulsar Spark source for streaming and batching queries.
Prerequisites
- Deploy the Pulsar Spark connector.
- Install Scala 2.12.10.
- Install Spark 3.1.1.
- Install Pulsar 2.4.2+ (tested with Pulsar 2.7.2).
Create a Pulsar Spark source for streaming queries
This example shows that the Pulsar Spark source reads data from one Pulsar topic (
topic1) to the Spark cluster.val df = spark .readStream .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topic", "topic1") .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]This example shows that the Pulsar Spark source reads data from multiple Pulsar topics (
topic1andtopic2) to the Spark cluster.val df = spark .readStream .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topics", "topic1,topic2") .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]This example shows that the Pulsar Spark source subscribes to a topic pattern.
val df = spark .readStream .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topicsPattern", "topic.*") .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]
Tip
For more information on how to use other language bindings for Spark structured streaming, see Structured Streaming Programming Guide.
Create a Pulsar Spark source for batch queries
For batch processing, you can create a Dataset/DataFrame for a defined range of offsets.
This example shows how a Pulsar Spark source reads data from one topic (
topic1) from the very beginning (earliest) to the newest records (latest) that are written after the Reader starts running.val df = spark .read .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topic", "topic1") .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]This example shows how a Pulsar Spark source reads data from multiple topics (
topic1andtopic2) from the specific offset.import org.apache.spark.sql.pulsar.JsonUtils._ val startingOffsets = topicOffsets(Map("topic1" -> messageId1, "topic2" -> messageId2)) val endingOffsets = topicOffsets(...) val df = spark .read .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topics", "topic1,topic2") .option("startingOffsets", startingOffsets) .option("endingOffsets", endingOffsets) .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]This example shows how a Pulsar Spark source subscribes to a topic pattern with
earlieststarting offset andlatestending offset.val df = spark .read .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topicsPattern", "topic.*") .option("startingOffsets", "earliest") .option("endingOffsets", "latest") .load() df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .as[(String, String)]
Write data to Pulsar
The DataFrame written to Pulsar can have arbitrary schema. Since each record in DataFrame is transformed as one message sent to Pulsar, fields of DataFrame are divided into two groups. __key and __eventTime fields are encoded as metadata of Pulsar messages. Other fields are grouped and encoded using AVRO and put in value().
producer.newMessage().key(__key).value(avro_encoded_fields).eventTime(__eventTime)
Prerequisites
- Deploy the Pulsar Spark connector.
- Install Scala 2.12.10.
- Install Spark 3.1.1.
- Install Pulsar 2.4.2+(tested with Pulsar 2.7.2).
Create a Pulsar Spark sink for streaming queries
This example shows how to write key-value data from a DataFrame to a specific Pulsar topic (
topic1).val ds = df .selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .writeStream .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topic", "topic1") .start()This example shows how to write key-value data from a DataFrame to Pulsar using a topic specified in the data.
val ds = df .selectExpr("__topic", "CAST(__key AS STRING)", "CAST(value AS STRING)") .writeStream .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .start()
Create a Pulsar Spark sink for batch queries
This example shows how to write key-value data from a DataFrame to a specific Pulsar topic (
topic1).df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)") .write .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .option("topic", "topic1") .save()This example shows how to write key-value data from a DataFrame to Pulsar using a topic specified in the data.
df.selectExpr("__topic", "CAST(__key AS STRING)", "CAST(value AS STRING)") .write .format("pulsar") .option("service.url", "pulsar://localhost:6650") .option("admin.url", "http://localhost:8080") .save()
Limitations
Currently, we provide at-least-once semantics. Therefore, when writing either streaming queries or batch queries to Pulsar, some records may be duplicated. A possible solution to remove duplicates could be to introduce a primary (unique) key that can be used to perform deduplication when reading data.