This connector is available as a built-in connector on StreamNative Cloud.
Quick start
Prerequisites
The prerequisites for connecting a Snowflake sink connector to external systems include:- Prepare a snowflake account
-
Get the account URL from the
Admin - Accountspage and click the link. It should be the format likehttps://<account_identifier>.snowflakecomputing.com. - Generate the public key and private key for the authentication. For more details, please check this guide
rsa_key.p8 (the private key) and rsa_key.pub (the public key) locally.
- Log in and configure the public key.
-a is followed by an account identifier, which is a substring of the account URL before. The -u is followed by your user name. After logging in, set the public key passphrase:
(MIIBIjA…) by running the following command:
1. Create Snowflake objects and grant permission
Before creating the connector, you need to grant the permissions in Snowflake. Write the following content into a file, e.g. name it withgrant.sql. The script creates a user snservice that will be used in the sink config later and associate it with a role snrole that is only used in Snowflake internally. Then it grants the necessary permissions.
2. Create a connector
The following command shows how to use pulsarctl to create abuiltin connector. If you want to create a non-builtin connector,
you need to replace --sink-type snowflake with --archive /path/to/pulsar-io-snowflake.nar. You can find the button to download the nar package at the beginning of the document.
If you are a StreamNative Cloud user, you need set up your environment first.
--sink-config is the minimum necessary configuration for starting this connector, and it is a JSON string. You need to substitute the relevant parameters with your own.
You can get the private key passphrase (MIIBIjA…) by running the following command:
You can also choose to use a variety of other tools to create a connector:
- pulsar-admin: The command arguments for
pulsar-adminare similar to those ofpulsarctl. You can find an example for StreamNative Cloud Doc. - RestAPI: You can find an example for StreamNative Cloud Doc.
- Terraform: You can find an example for StreamNative Cloud Doc.
- Function Mesh: The docker image can be found at the beginning of the document.
3. Send messages to he topic
If your connector is created on StreamNative Cloud, you need to authenticate your clients. See Build applications using Pulsar clients for more information.
4. Check the data on Snowflake table
First, you need to execute the following SQL command to grant the roleSNROLE to the user you logged in.
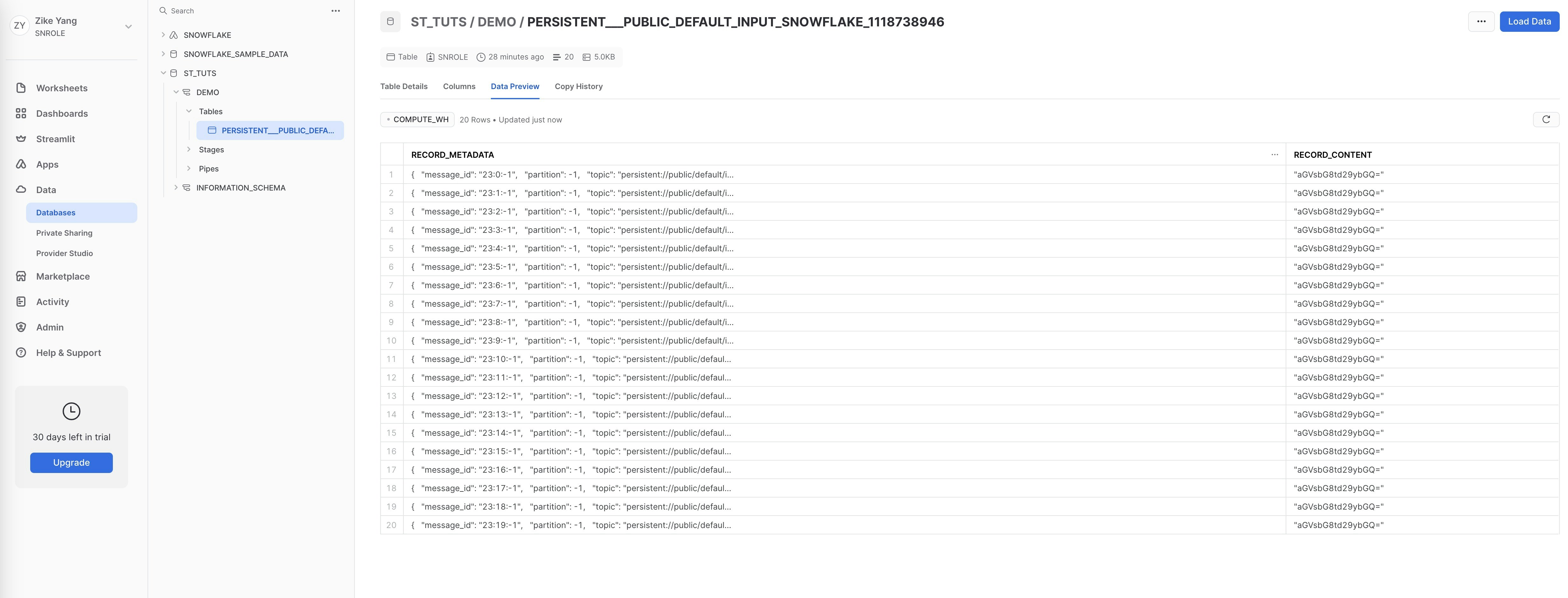
SNROLE, under Data - Database - ST_TUTS - DEMO - Tables you will find table PERSISTENT___PUBLIC_DEFAULT_INPUT_SNOWFLAKE_1118738946 is created and records the messages produced above.
Configuration Properties
This table outlines the properties and the descriptions.| Name | Type | Required | Sensitive | Default | Description |
|---|---|---|---|---|---|
user | String | Yes | false | ""(empty string) | The user account name of the Snowflake service. |
privateKey | String | Yes | true | ""(empty string) | The private key of the user. |
host | String | Yes | false | ""(empty string) | The host URL of the snowflake service. |
database | String | Yes | false | ""(empty string) | The Snowflake database where the connector will sink data. |
schema | String | Yes | false | ""(empty string) | The Snowflake schema belongs to the level below the Snowflake database and consists of a set of tables. |
tableName | String | No | false | ""(empty string) | If the autoCreateTable option is set to false, the Snowflake connector will persist messages to this table. |
warehouse | String | No | false | ""(empty string) | The warehouse name in the snowflake. By default, no warehouse name is set. |
bufferCountRecords | int | No | false | 10_000 | The number of records that are buffered in the memory before they are ingested to Snowflake. By default, it is set to 10_000. |
bufferSizeBytes | int | No | false | 5_000_000 | The cumulative size (in units of bytes) of the records that are buffered in the memory before they are ingested in Snowflake as data files. By default, it is set to 5_000_000 (5 MB). |
bufferFlushTimeInSeconds | int | No | false | 60 | The number of seconds between buffer flushes, where the flush is from the Pulsar’s memory cache to the internal stage. By default, it is set to 60 seconds. |
autoCreateTable | boolean | No | false | false | Automatically create a table when the table does not exist. |
processingGuarantees | String | No | false | ”ATLEAST_ONCE” | Specify the processing guarantee semantics. Currently, the Snowflake connector only supports ATLEAST_ONCE processing guarantee semantics. |
topic2table | String | No | false | ""(empty string) | Specify the mapping relationship between topics and tables. The topic name should be its complete name. Each topic and the mapped table name should be separated by a colon, such as persistent://public/default/topic1:table1,persistent://public/default/topic2:table2. |
metadataField | String | No | false | ”message_id,partition,topic,event_time” | The metadata fields for each snowflake record. You can separate multiple fields with commas. The supported metadata fields are: schema_version , partition , event_time , publish_time , message_id , sequence_id , producer_name , topic. Currently, the Snowflake sink connector currently does not support custom metadata. |
Advanced features
This section describes the advanced features of the Snowflake sink connector. For details about how to configure these features, see how to configure.Delivery guarantees
The Pulsar IO connector framework provides three delivery guarantees:at-most-once, at-least-once, and effectively-once.
Currently, the Snowflake sink connector only supports the at-least-once delivery guarantee semantic.
Table name mapping
The Snowflake sink connector supports automatically creating a table when the table does not exist. You can configure the following options:topic2table see example below:
Metadata Fields
There are two fields in the table: metadata and content. Metadata is ancillary information in content, such astopic, messageId, publishTime, and so on.
By default, the following metadata fields of Pulsar will be created as the metadata:
Note Currently, the Snowflake sink connector does not support custom metadata.
Data format types
The snowflake connector supports converting some Pulsar schemas, as listed in the following table.| Pulsar Schema | Supported |
|---|---|
| AVRO | Yes |
| PRIMITIVE | Yes |
| JSON | Yes |
| KEY_VALUE | No |
| PROTOBUF | No |
| PROTOBUF_NATIVE | No |
| Schema Type | Converted Content | Example |
|---|---|---|
| BYTES | Base64-encoded String | ”SGVsbG8=” (Hello in base64) |
| Boolean | Boolean | true |
| INT8, INT16, INT32, INT64, FLOAT, DOUBLE | Number | 1234 |
| STRING | String | ”Hello” |
| JSON | JSON Object | {"name": "John", "age": 30} |
| AVRO | JSON Object | {"name": "John", "age": 30} |
| DATE, TIME, TIMESTAMP | Number (milliseconds since Jan 1, 1970, GMT) | 1654849667447 |
| INSTANT | Number (seconds since 1970-01-01T00:00:00Z) | 1654826254.091 |
| LOCAL_DATE | Array [Year, Month, Day] | [2022, 12, 1] |
| LOCAL_TIME | Array [Hour, Minute, Second, Nanosecond] | [16, 30, 28, 150000000] |
| LOCAL_DATE_TIME | Array [Year, Month, Day, Hour, Minute, Second, Nanosecond] | [2022, 12, 1, 16, 30, 28, 150000000] |